




















A deepfake detection system that returns "fake — 87% confidence" with no further explanation is operationally insufficient in 2026. Compliance officers can't defend it in audit. Courts won't admit it as evidence. Insurance carriers won't underwrite around it. Security analysts can't triage it. The black-box detector — accurate but opaque — is being squeezed out of the market by a simple commercial reality: every major IDV procurement process now asks vendors to show their work.
This guide explains what explainable AI (XAI) means in the specific context of deepfake detection, the techniques the industry has converged on, why explainability has moved from a research nice-to-have to a buying requirement, and what a credible XAI deepfake detection product actually looks like. It is written for IDV product managers, compliance leads, and security architects who need to evaluate detection vendors against the standards regulators and auditors are now applying.
If you're earlier in the journey, our introduction to deepfakes, our explainer on how deepfakes are made, and our practical detection guide cover the foundational material this guide builds on.
- EU AI Act Article 13 requires that high-risk AI systems be designed so users can interpret their outputs — black-box deepfake detection no longer satisfies this standard.
- The dominant XAI techniques in deepfake detection: Grad-CAM (visual saliency), SHAP (game-theoretic feature attribution), and LIME (local model-agnostic explanations).
- Production XAI deepfake detection produces three outputs simultaneously: per-frame heatmap, feature-attribution table, and a plain-language summary.
- Newer concept-level XAI methods (DPNet, Concept Activation Vectors) explain decisions in human-meaningful terms rather than raw heatmaps.
- Major IDV procurement processes now ask vendors for per-frame explainability, architecture-aware detection (GAN vs diffusion), and exportable audit trails.
- XAI is also a defensive layer: adversarial attacks on detectors often shift model attention to anomalous regions, which interpretability makes visible.
What Is Explainable AI in Deepfake Detection?
Explainable AI (XAI) is a family of techniques that makes the decisions of machine learning models interpretable to humans. Rather than producing only a final classification — "real" or "fake," with a confidence score — an XAI-enabled detector also produces reasons: which regions of the image the model focused on, which features contributed most to the decision, and how the model's reasoning compares to known artifact patterns.
In the specific context of deepfake detection, explainability typically takes one of three forms:
- Spatial explanations — heatmaps overlaid on the input image or video frame, showing which pixels drove the model's verdict. The mouth, the jawline, and the eye region might light up in red while the rest of the frame remains neutral.
- Feature attributions — a ranked list of the input features (frequency bands, color channels, temporal segments) and how much each contributed to the prediction.
- Concept-level explanations — descriptions in human-meaningful terms: "this image was flagged because the model detected diffusion-style high-frequency texture residuals concentrated in the cheek and forehead regions."
A 2025 review of XAI techniques applied to deepfake detection identified three dominant methods in active research and deployment: Grad-CAM (gradient-weighted class activation mapping) for visual saliency, LIME (local interpretable model-agnostic explanations) for feature attribution on individual predictions, and SHAP (SHapley Additive exPlanations) for game-theoretic feature attribution. Each operates at a different level of abstraction; effective production systems use more than one.
The goal is not to make the underlying neural network simpler. It is to make its decision defensible — to a compliance officer, a fraud analyst, an auditor, a regulator, or a court.
Why Black-Box Detection Is No Longer Acceptable
Three forces have moved explainability from a research preference to a procurement requirement.
Regulatory pressure. The EU AI Act classifies many deepfake detection deployments as high-risk AI systems, with corresponding requirements for transparency, traceability, and human oversight. Article 13 requires that high-risk systems be designed so users can interpret their outputs and use them appropriately. A black-box "fake — 87%" verdict does not satisfy that standard. Similar transparency requirements appear in the U.S. NIST AI Risk Management Framework, in Singapore's Model AI Governance Framework, and in the financial services AI guidance from the OCC, ECB, and FCA. The trend is one-directional.
Legal admissibility. When deepfake evidence reaches a courtroom — increasingly common in fraud, defamation, and non-consensual intimate imagery cases — the prosecution or defense must explain why a piece of media was classified as synthetic. A research paper from 2025 noted explicitly that detection systems lacking interpretability are "impractical in domains where evidence must be transparent and verifiable, such as law or journalism." Courts have begun rejecting black-box AI evidence in favor of systems that can produce evidentiary chains an expert can defend on the stand.
Operational reality. Security analysts triaging hundreds of flagged events per day cannot act on raw scores. They need to see what the system saw — a heatmap on the suspicious region, a frequency-domain signature, a comparison to known artifact patterns — to decide whether to escalate, dismiss, or request human review. Without explanation, the analyst either trusts the system blindly (dangerous) or distrusts every flag and burns time re-investigating (operationally unworkable).
Adversarial robustness. XAI techniques also help defenders identify when a detector is being attacked. If an analyst sees the model attending to the wrong regions of an image — focusing on the background instead of the face — that is a strong signal of an adversarial perturbation designed to fool the detector. Recent research on XAI-based detection of adversarial attacks on deepfake detectors has shown that interpretability is not just a transparency feature; it is a defensive layer.
The combination is unambiguous: detection without explanation is a liability. A 2025 review of explainable deepfake detection techniques concluded that integrating XAI methods makes models "more trustworthy and interpretable" and that the goal is to "develop effective and transparent models" rather than choosing between accuracy and explainability.
The Core XAI Techniques
The XAI literature is large, but in deepfake detection a small set of techniques covers the vast majority of practical deployments.
The choice depends on what kind of explanation the downstream user needs. A fraud analyst reviewing a flagged identity submission usually wants a visual heatmap. A compliance officer documenting a decision usually wants a feature-attribution table. A research scientist debugging a model wants concept-level analysis. Production systems typically expose more than one of these views.
Visual Saliency: Grad-CAM and Its Successors
Grad-CAM (Selvaraju et al., 2017) is the workhorse of visual XAI. The technique computes the gradient of the model's output (the "fake" classification) with respect to the activations of the last convolutional layer, then weights and combines those activation maps to produce a heatmap showing which spatial regions most strongly influenced the decision.
For deepfake detection, Grad-CAM heatmaps typically highlight one of a small set of regions:
- Boundary regions — jawline, hairline, neck. Common in autoencoder face-swap detection because boundary blending leaves residual artifacts.
- Eye region — sclera, iris, eyelid edges. Common when the model is using physiological signals (rPPG, micro-saccades) or detecting eye-region asymmetry.
- Mouth and teeth — lip movement and dental texture. Common in lip-sync deepfake detection and in models that catch tooth-rendering imperfections.
- Forehead and cheek texture — broad areas with consistent skin. Common in diffusion-content detection where high-frequency texture residuals manifest.
Grad-CAM has known limitations: the resolution is constrained by the spatial resolution of the last conv layer (often 7×7 or 14×14, then upsampled), and it can produce slightly diffuse heatmaps. Successors — Grad-CAM++, Score-CAM, Eigen-CAM — improve precision and generalize to non-CNN architectures including vision transformers. Modern production systems often use a transformer-aware variant: attention rollout or token-level attribution that highlights which patch tokens the model attended to.
Feature Attribution: SHAP and LIME
Where saliency maps tell you where in the image the model looked, feature attribution tells you how much each feature contributed to the decision and in what direction (toward "real" or toward "fake").
SHAP (SHapley Additive exPlanations) uses cooperative game theory to assign each feature a contribution value that satisfies a set of mathematical fairness axioms. Applied to deepfake detection, SHAP can quantify the contribution of, say, the discrete cosine transform coefficients in different frequency bands, or — for audio — the contribution of different cepstral coefficients. SHAP values are particularly valued by compliance teams because they produce a numerically defensible per-feature breakdown that can be documented and audited.
LIME (Local Interpretable Model-Agnostic Explanations) approximates the complex model's decision in the local neighborhood of a specific input by fitting a simple, interpretable model (often a sparse linear regression) to perturbations of that input. For deepfake images, LIME might mask different superpixels of the face and observe how the model's prediction changes, producing a per-superpixel importance score.
The two techniques complement each other. SHAP gives globally consistent attributions but is computationally expensive. LIME is faster but produces explanations that can vary across runs (it relies on random sampling). A 2025 forensic speech authentication paper applied both Grad-CAM and SHAP to a CNN+LSTM voice deepfake detector, finding that the model focused on high-frequency artifacts and temporal inconsistencies — which validated the model's design and the relevance of the chosen acoustic features.
For practitioners, the most useful pattern is: SHAP for the audit trail and the regulatory documentation, LIME for fast per-incident analysis, Grad-CAM for the analyst-facing UI.
Prototype-Based and Concept-Based Explanations
A newer family of XAI techniques — increasingly important in deepfake detection — moves beyond pixel-level explanations to concept-level ones: explanations expressed in terms a human reviewer naturally uses.
DPNet (Dynamic Prototype Network) is a representative example. Rather than producing a heatmap, DPNet learns a small set of prototype patterns that represent common temporal inconsistencies in deepfake videos — things like "abrupt jaw boundary shift across frames" or "rPPG signal discontinuity at frame 47." When the model flags a video, it does so by saying: "this clip activated prototype #4, which represents jaw-boundary instability." That kind of explanation is dramatically more useful to a non-technical analyst than a raw heatmap.
Concept activation vectors (CAVs) push this further: a model is probed to determine whether it has internally represented human-meaningful concepts (e.g. "skin texture smoothness," "lip-sync misalignment"), and then explanations are expressed in terms of those concepts.
The 2025 literature on multimodal explainable deepfake detection emphasizes pipelines that "unify prediction and explanation in a coherent, human-aligned pipeline." The vision is a system that not only flags a clip as synthetic but produces a structured, natural-language explanation: "Flagged due to (a) diffusion-style high-frequency texture residuals in the cheek region, (b) lip-audio sync drift averaging 67ms, (c) absence of rPPG pulse signal." That is the format that compliance teams, courts, and security analysts can all act on.
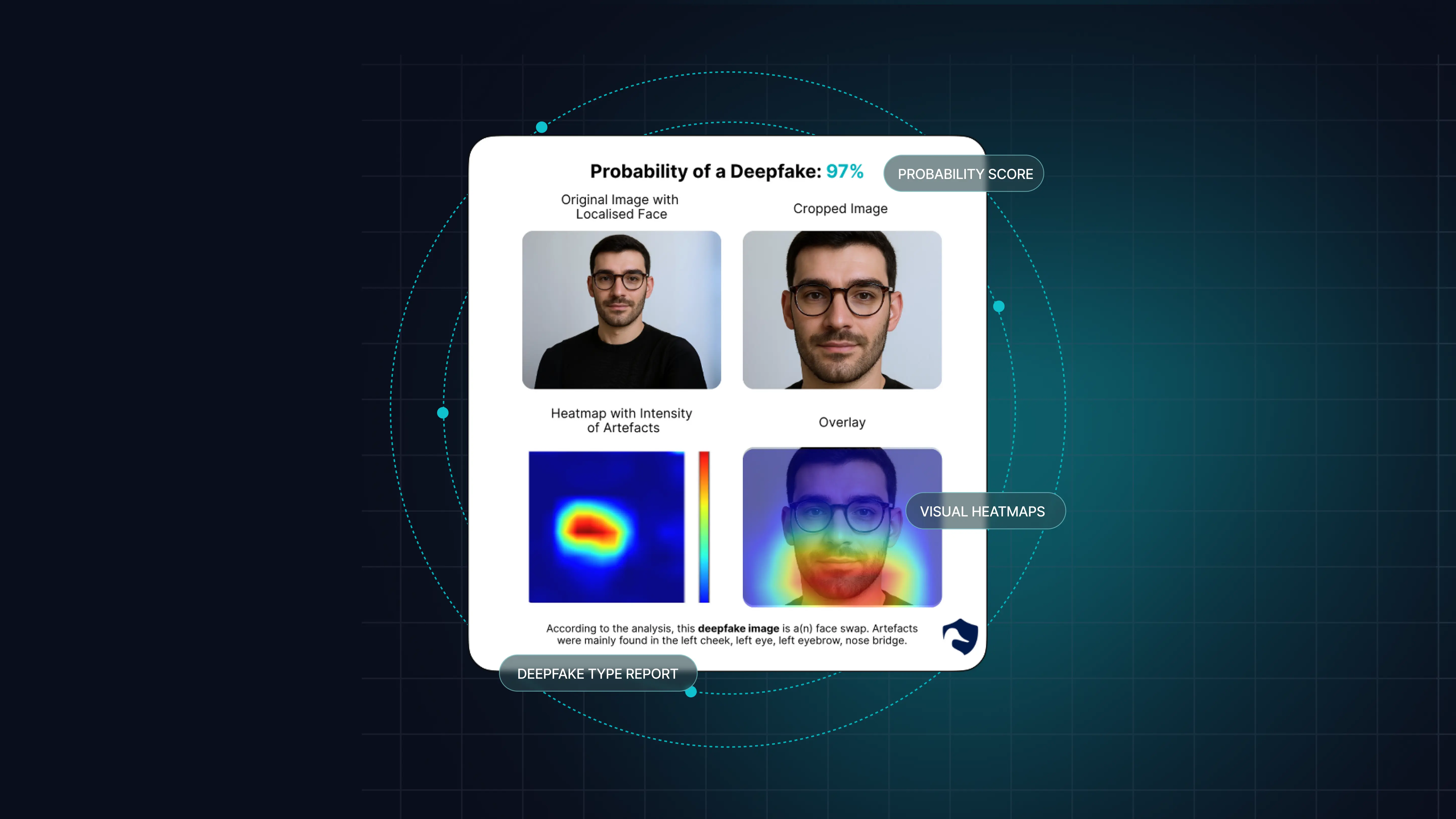
DuckDuckGoose's DeepDetector is built around this principle: every detection verdict is paired with a structured, multi-level explanation — a per-frame heatmap for visual review, an architecture-level attribution showing which underlying model fired (GAN-detector, diffusion-detector, autoencoder-detector), and a human-readable summary suitable for compliance documentation.
Audio Deepfake Explainability
Voice deepfake detection has its own XAI challenges. The input is one-dimensional audio rather than a 2D image, but the same broad principles apply.
The standard approach is to convert the audio to a 2D representation — a mel-spectrogram or a stack of cepstral coefficients — and then apply image-domain XAI techniques like Grad-CAM and SHAP to that representation. A heatmap on a mel-spectrogram tells the analyst that the model attended primarily to, for example, the 4–8 kHz frequency band during a specific 200ms window — which corresponds to the high-frequency artifacts that cloned voices commonly leak.
A 2025 study on forensic speech authentication applied Grad-CAM and SHAP to a CNN+LSTM voice deepfake detector trained on the ASVspoof 2019 LA and WaveFake datasets. The XAI analysis revealed that the model focused on high-frequency artifacts and temporal inconsistencies — both of which match the underlying physics of how voice cloning models leak detectable signal. That alignment between what the model attends to and what the underlying physics says it should attend to is exactly the validation that regulators and courts increasingly require.
The downstream analyst output — for a contact center or a voice-call deepfake detection system — typically consists of three components: a per-clip verdict, a spectrogram heatmap, and a list of detected anomalies in plain language ("unusually smooth pitch contour from 0:23 to 0:31; missing breath intake before 'transfer' at 0:34; elevated 6-8 kHz spectral artifacts consistent with neural-codec resynthesis").
Where XAI Is Now Required
XAI in deepfake detection has moved from research labs into specific operational contexts where it is now a non-negotiable.
The pattern is consistent: any context where a detection verdict is acted on by a human, or defended in front of an external party, requires explanation. Pure machine-to-machine deployments — say, automated content moderation where false positives have low cost — can sometimes operate with raw scores. But identity verification, fraud investigation, regulatory compliance, and legal proceedings all now expect interpretable evidence.
For IDV providers specifically, this is showing up in RFP requirements. Deepfake detection vendor evaluations increasingly include questions like: "Can you provide per-frame explainability for flagged submissions?" "How does your system distinguish between GAN-style and diffusion-style artifacts?" "Can compliance teams export an audit trail showing what drove each verdict?" Vendors that cannot answer those questions are being eliminated from shortlists.
Evaluating XAI Deepfake Detection Vendors
When assessing detection vendors against XAI requirements, the following dimensions separate credible solutions from marketing claims.
A few diagnostic questions that quickly separate genuine XAI capability from a thin wrapper:
- "Show me a flagged false positive and explain why your model got it wrong." A vendor with real XAI can do this. A vendor with bolted-on saliency maps cannot.
- "What does your explanation look like for a diffusion-generated image vs. a GAN-generated image?" A credible system shows visibly different explanations because it has architecture-aware detection.
- "Can your system distinguish a deepfake from a heavily edited but real image?" Compression artifacts, color grading, and aggressive denoising can trigger false positives. A good XAI system shows that the model attended to the right kind of artifact, not just any artifact.
- "Does your explanation generalize across the languages and demographics in our user base?" Detection biased by training data shows up in explanations — if the model only ever attends to specific facial features for specific demographics, that is a fairness problem the explanation makes visible.
- "Can compliance teams export the full evidence package — verdict, heatmap, feature attribution, model version, dataset version — for any flagged event?" This is the audit-trail question, and it is becoming a hard regulatory requirement.
For benchmark accuracy data on deepfake detection systems in production conditions, see our detection accuracy analysis.
Common Pitfalls
A few patterns to watch for when adopting or building XAI deepfake detection.
Treating saliency maps as ground truth. A heatmap shows what the model attended to, not what is actually fake. A model attending to the right region for the wrong reason is still wrong. Saliency is a window into the model, not into reality.
Using explanations to over-trust the model. "The system showed me a heatmap, so it must be right" is a cognitive trap. Explanations should support critical analyst review, not replace it. The best practice is to require analyst sign-off on high-stakes flags, with the explanation as supporting evidence.
Forgetting that XAI is itself attackable. Adversarial inputs designed to fool the detector can also be designed to fool the explanation system — producing a "plausible-looking" heatmap on an actually-real image. Robust XAI systems include sanity checks (does the heatmap correlate with the kind of artifact the model claims it detected?) and ensemble explanations.
Confusing interpretability with simplicity. A complex ensemble model can be highly interpretable if it is paired with the right XAI tooling. A simple linear model can be opaque if its inputs are themselves complex learned embeddings. Interpretability is about the interface between model and human, not the underlying architecture.
Skipping the documentation step. Explanations are only useful if they are persisted, versioned, and tied to model versions and data versions. An explanation produced today by a model that was retrained tomorrow is not a defensible audit artifact unless the model snapshot and dataset snapshot are stored alongside it. This is where many otherwise-strong XAI implementations fail in production.
FAQ
What is explainable AI in the context of deepfake detection? Explainable AI (XAI) in deepfake detection refers to techniques that make a detector's decisions interpretable: showing which regions of an image drove the verdict (saliency maps), how much each input feature contributed (feature attribution), and providing human-readable summaries of the reasoning. The goal is to produce evidence a security analyst, compliance officer, or court can act on — not just a numerical confidence score.
Why does deepfake detection need to be explainable? Three reasons: regulation (the EU AI Act and similar frameworks require transparency for high-risk AI), legal admissibility (courts increasingly require that AI-driven evidence be defensible by an expert), and operational reality (analysts and compliance teams cannot effectively act on opaque scores). Black-box detection is becoming a procurement disqualifier in IDV and enterprise security.
What's the difference between Grad-CAM, LIME, and SHAP? Grad-CAM produces visual heatmaps showing which pixels the model attended to, using gradients from the last convolutional layer. LIME approximates the model locally with a simple interpretable model to attribute the contribution of input features. SHAP uses cooperative game theory to assign mathematically principled feature contributions. They are complementary: Grad-CAM for analyst-facing visuals, SHAP for audit-trail documentation, LIME for fast per-incident attribution.
Can XAI techniques fool the user with misleading explanations? Yes — this is a real concern. Adversarial inputs can sometimes produce plausible-looking explanations on actually-clean images, and explanations themselves can be manipulated. Robust deployments use ensembles of XAI methods, sanity checks, and human review for high-stakes decisions. Explanations should support analysis, not substitute for it.
How does explainability help against adversarial attacks? When a detector is under adversarial attack, its attention often shifts to unusual regions of the input — the background, an irrelevant patch, or a uniform area. XAI heatmaps make this shift visible to analysts, who can flag the input for additional scrutiny. Recent research has formalized this into XAI-based adversarial-attack detection systems that operate alongside the primary detector.
Is explainability required by law for deepfake detection systems? In the EU, yes, for high-risk deployments under the AI Act — Article 13 requires transparency and interpretability. In the U.S., it is encouraged by the NIST AI Risk Management Framework and required by sector-specific regulators (banking, healthcare). Globally, the trend is toward mandatory transparency for AI used in high-stakes decisions, including identity verification and fraud detection.
How do I evaluate whether a vendor's "explainability" is real or marketing? Ask for a flagged false positive and a detailed explanation of why the model was wrong; ask for explanations on both GAN and diffusion content (they should look different); ask whether explanations include model and dataset versioning for audit; and ask whether compliance teams can export the full evidence package. Vendors with thin saliency-map wrappers cannot answer these well.
What does an XAI deepfake detection workflow look like in practice? A flagged event arrives in a security analyst's queue. The analyst sees the original media, a verdict ("synthetic — diffusion-style, 91% confidence"), a heatmap highlighting the cheek and eye regions, a feature-attribution table showing the top contributing frequency bands and temporal segments, and a plain-language summary. The analyst either confirms the flag (with one click, capturing the explanation as part of the audit trail), escalates for human review, or marks it as a false positive — feeding back into model improvement. The whole loop, with explanation, takes seconds.
Detection without explanation is a procurement liability in 2026. DuckDuckGoose's DeepDetector provides per-prediction explainability across GAN, autoencoder, and diffusion content — designed for IDV providers, compliance teams, and security analysts who need defensible verdicts. Talk to our team about XAI requirements in your detection deployment.
Last update: Q2 2026.
.png)
About the author











